Abstract
In the context of the advanced practical course “Application Challenges for Machine Learning on the example of IBM Power AI” our task was to build a complete system around the topic of music genre detection. During the project, we complemented this base functionality with various other features and created a mobile application for Android and iOS that helps the user to explore music and extend their personal music landscape in a fun and interactive way. Due to this main goal, we named our App Spektrum.

Two major machine learning tasks in the field of musical analysis were solved during this project: music genre detection and music recommendation. We made extensive use of external data sources for collaborative and content-based filtering and incorporated external APIs to increase the value of our app. While the Audd API is used for identifying the recorded songs, the Spotify API is leveraged throughout our whole application.
The entire backend of Spektrum is hosted on the IBM AC922 at TUM to make the functionality of our app globally accessible. We implemented a micro-service system with over 40 different API endpoints to cover all our use-cases.
In the end, we created a genre classifier trained with Spotify song samples that is able to distinguish 20 different genres with an accuracy of over 70%. Moreover, we built a recommender system for songs, artists and playlists that is based on three data sources and supports the user in their musical discovery. Over 100 single and multiplayer quizzes, a genre quiz where the user competes against our trained neural network, a playlist generator as well as user statistics complete the feature set of Spektrum.
Team Introduction and Organisation
Team Roles
Our team consisted of five people and each team member covered two main responsibility areas. A more detailed overview of responsibilities is given in the Responsibilities chapter at the end of this document.

Project Manager & Frontend Developer

Frontend Developer &
IT Architect

IT Architect &
Backend Developer

Data Scientist & Backend Developer

Frontend Developer & Frontend Team Lead
Project Organisation
In terms of project organisation, the key element was to hold at least one meeting per week with the whole team in order to bring everyone up to date and to connect frontend and backend development efforts. Inside the subteams, several meetings were held, depending on the current workload and expertise of the respective members. Issues and tasks that were discussed during the meetings were assigned to one team member in order to have clear responsibilities and no redundant work.
To be able to view the progress of each team member, integrate new features seamlessly and track issues, we created three separate Gitlab repositories that were accessible to every member: Frontend, Backend, and Data Science. All other files (e.g. some song datasets, presentation, documentation) were stored on a shared Google Drive folder which enabled us to simultaneously work on the deliverables.
Project Plan

The project plan that was presented during the intermediate presentation was not completely adhered to. REST-API development as well as frontend development took longer than expected.
Backend-wise, the REST-API delay can be explained by the huge variety of endpoints that were added throughout the project, new requirements and ideas on how to improve the application came up every week.
On the frontend side, it has to be said that most of the team members were new to the technologies (React Native, Redux, Expo) that were used and it took some time to become acquainted with them. However, due to the fact that some time buffer was integrated into our initial project plan, overall, the project was finished on time and all milestones were successfully reached.
1. Project Topic and Motivation
1.1. Project Topic
Our task in this project was to build a complete system around music genre detection. We also needed to implement at least one other functionality within the field of music analysis, and as the project evolved this resulted in music recommendations, music quizzes, playlist generation and user statistics. The task required us to explore the theoretical background of machine learning for music analysis, as well as figuring out how a potential user can benefit from an exploration within the musical world. We were given a lot of freedom as to how we should build this system. We chose to create a mobile application for Android and iOS, with the goal to help people explore music in an interactive and fun way. The result is our mobile application Spektrum that is described in detail in the remainder of this documentation.
1.2. Motivation and Theoretical Foundation
Starting with this project we wanted to get a better understanding of different challenges that exist in the domain of music analysis. All of us are big fans of music, and we looked at other music apps to get inspiration for potential features. In this section, we will present the theoretical foundation and what motivation influenced our project.
Music Genre Classification
In the early 2000s, Music Genre Classification has become a relevant topic within machine learning since it decreases the effort of tagging large music databases significantly [1]. In recent years, machine learning models have managed to achieve the same level of accuracy as humans with the use of convolutional neural networks (CNN) covering over 10 genres [2]. Although models now outperform human performance which is often limited by knowledge and subjectivity, machine learning still faces challenges in further improvement due to the lack of clear boundaries between genres [3]. We were interested in gaining knowledge about which genres are particularly hard to differentiate, and maybe also recognize some categories that often overlap. Based on our final application, we hope to end up with a tool to gain valuable insights for identifying more distinctive properties between genres. This could help to define more precise rules for music classification to further improve accuracy.
Music Recommendation System
Recommender systems have become a big part of our daily online life, and are largely used to increase user experience and aim to predict a users’ interests [4]. All of us have experienced the cunning accuracy from recommendation systems on Amazon and Spotify who aim to to increase the platform usage, and we were curious to learn how it works and how to build our own recommendation system. Collaborative filtering is a common technique used to give personalized music recommendations and is done by comparing historical preferences of users with similar music profiles [5]. Another approach that has been promising is content-based filtering, which looks at songs’ acoustic similarity and proposes the song with the minimum distance [6].
Gamification
Gamification is the use of game mechanics in order to engage users [7] and has been a big part of a lot of popular mobile apps in recent years [8]. This method has been proven to increase how much time users spend on an app, scientifically supported by the fact that playing games increases our dopamine levels [9]. Gamification also often awakes curiosity [10], which aligns with our goal to have users further explore Spektrum. We want to give the user a sense of skill development while they explore our wide selection of quizzes and one way we did this was keeping a highscore in our single-player mode. With the additional ability to play against friends with our multiplayer mode, we think our app will entertain a variety of users.
As pointed out previously, music genre detection cannot always follow set rules which distinguish genres from each other - it might even be up to subjective opinions. There is also a possibility that there are more than one genre that describes a song. This, combined with the reported success of game-apps, lead to the idea of our main quiz type. Here the user competes against our machine learning model to shed some light on what songs the model and the user agrees and disagrees on. This could be important in further research to optimize genre classification since it could be used as a tool to document which genres are especially controversial.
2. Features and Functionality
After the drafting and specification of our project idea as described in the previous chapter, we have separated the functionality into three areas. First, the Identify page is centered around identifying a recorded song and predicting its genre. Second, the Discover page provides rich opportunities to explore new music based on the user’s unique music taste. And third, the Play page enables the user to test and improve their music knowledge in a fun and interactive way by playing a variety of music quizzes. In the following part, we provide a short functionality overview, for more detailed explanations and screenshots see chapter 5.

Identify: This is the starting page of our app and gives the user the opportunity to record any music piece such as a radio song or even a live musician to analyze the music with respect to its genre characteristics. The cool implementation part here is that the user not only receives a single guess of the genre but a pie chart with probabilities for several genres according to our machine learning model to get a bigger picture of the genre characteristics of this specific song. If the user records a professional song, we also display the name, artist and give them the option to open the song in Spotify, e.g. to add it to a playlist.
Discover: This page would be an obvious choice to switch to after having identified one or multiple songs. While we provide the user with all kinds of music recommendations such as other songs and artists based on the previously identified songs, we can also show some recommendations based on worldwide Spotify trends. Based on the user’s Spotify library the user is also able to review their music taste in terms of favourite songs, artists, decades and genres. Another cool feature we implemented is a playlist generator that allows the user to generate playlists and add them to their Spotify library with respect to detailed music features such as danceability or happiness.
Play: Finally, after exploring new music the user is able to test and extend their music knowledge by playing one of more than 100 different music quizzes. One main quiz is to guess the genre of a song in competition against our latest machine learning model. It is especially interesting for us as developers to compare the trained genre classifier with human experience. Furthermore, there are quizzes to guess songs (played normally, in 8-bit format or reversed), artists, decades and genres within different subcategories as further explained in chapter 5. Another cool functionality is that the user can not only play against our AI and beat their high score in single-player mode but also play against a friend in multiplayer mode. We are sure that this motivates the user even more to improve their music knowledge.
3. Solution Architecture
The architectural diagram below depicts the general flow of our application and provides an overview of our service landscape.

3.1. Frontend
React Native and Redux
As described in the previous sections we focused our development efforts on a mobile application. This was the best fit for our use case and presented itself as a modern solution to tackle problems in music analysis. In order to support multiple platforms and simplify development, we rely on the React Native framework. React Native is an open-source mobile application framework created by Facebook. It is used to develop applications for Android, iOS, Web and UWP (Universal Windows Platform) by allowing developers to use the JavaScript-based framework React along with native platform capabilities [11]. Alongside React and React Native we are also using Redux to manage the state of our application. This allows us to share information such as the currently identified song amongst the components.
Expo
We decided to use Expo, a free and complete workflow framework for creating our app for iOS and Android. With Expo tools, services, and React, you can build, deploy, and quickly iterate on native Android, iOS, and web apps from the same JavaScript codebase [12]. This simplified development for our frontend team by allowing rapid prototyping and easy sharing of new features.
3.2. Backend
Rest-API
The Python package Flask is utilised to create a modern REST-API. Flask simplifies the development of a stateless RESTful web service that can be consumed by the React Native frontend. The API is designed to allow simple CRUD operations on the defined objects as well as more complicated queries [13]. All available endpoints are described below, including endpoints such as identifying a song or retrieving a newly generated quiz. Furthermore, we decided to document our API using the Swagger Toolkit. Swagger is an open-source software framework that helps developers design, build, document, and consume RESTful web services [14]. It allows bridging the gap between Frontend and Backend development, simplifying communication and testing.
An overview of all our REST-API endpoints is depicted in the following:

Authentication Endpoint <API>/auth
This endpoint handles the entire authentication flow between the mobile application and the backend, including Spotify token validation, user account creation and JWT token validation.
Song Endpoint <API>/song
The song endpoint is the pivotal point of our application. It allows identifying songs and classifying their genre. Furthermore, it also provides the functionality to retrieve the history of previously identified songs.
Recommendation Endpoint <API>/recommend
The recommendations delivered by this endpoint range from artists, songs and playlists based on the recognised song to more general recommendations like global charts.
UserLibrary Endpoint <API>/userlibrary
The Spotify library of the user can be fetched via this endpoint. For each song, general information as well as acoustic features are stored in the database.
Playlist Endpoint <API>/playlist
This endpoint allows the user to create custom playlists from their Spotify library depending on a set of parameters defined by the user, such as decade, danceability, acousticness, or popularity of songs. It then proceeds to create a playlist for the user’s Spotify account, where they can directly listen to it.
Statistic Endpoint <API>/statistic
This endpoint provides an overview of user preferences and their favourite artists, genres and decades. This is directly linked with the users Spotify account and preferences are retrieved from the Spotify API.
Quiz Endpoint <API>/quiz
This endpoint provides a multitude of potential dynamically generated quizzes, divided into different categories such as artist, decade, song or special categories like 8-bit or reverse song quizzes.
Genre Classifier Endpoint <API>/genreclassifier
The main responsibility of this endpoint is to expose the machine learning capabilities to create a more dynamic model training and also the potential for further extension of our machine learning models.
Database
A relational database is used to store meta-information about users and songs, such as the history of identified songs. Currently, we do not store song files in a database, however, this could be extended in the future and will be pointed out in the chapter on future work. In our production environment, we decided to integrate a Postgres database using SQLAlchemy in Python, which easily allows creating model files and abstract the database access in a service away from the REST controllers. For development and testing purposes we use a lightweight SQLite database.
The description of all defined entities and database schemas is presented below:
User
| Fields | Data Type | Description |
| deviceid | String | Device ID of the User |
| registered_on | DateTime | DateTime of the Registration of the User |
| spotify_auth_token | String | Spotify Authentication Token of the User |
| spotify_refresh_token | String | Spotify Refresh Token of the User |
| spotify_library_loaded | Boolean | Flag whether the Spotify Library of the User has already been downloaded |
Song
| Fields | Data Type | Description |
| artist | String | Artist of the Song |
| song | String | Song Title |
| spotify_song_id | String | Spotify Song ID |
| spotify_song_uri | String | Spotify Song URI |
| spotify_artist_id | String | Spotify Artist ID |
| cover_art | String | Cover Art |
| genre | String | Genre Classification of the Song |
UserLibrary
| Fields | Data Type | Description |
| deviceid | String | Device ID of the User that has this Song in their Library |
| songid | String | Spotify Song ID |
| audio_preview | String | Audio Preview of the Song |
| artist | String | Artist of the Song |
| song | String | Song Title |
| genre_of_artist | String | Genre of the Artist |
| year | Integer | Release Year of the Song |
| added_on_year | Integer | Year when the Song was added to the Library of the User |
| duration_in_sec | Float | Song Duration in Seconds |
| energy | Float | Energy Level of the Song |
| danceability | Float | Danceability Level of the Song |
| instrumentalness | Float | Instrumentalness Level of the Song |
| liveness | Float | Liveness Level of the Song |
| valence | String | Valence Level of the Song |
| acousticness | Float | Acousticness Level of the Song |
| loudness | Float | Loudness Level of the Song |
| speechiness | Float | Speechiness Level of the Song |
| tempo | Float | Beats Per Minute of the Song |
| popularity | Float | Popularity Level of the Song |
| decade | String | Decade of the Song |
Playlist
| Fields | Data Type | Description |
| deviceid | String | Device ID of the User that built the Playlist |
| playlistid | String | Spotify ID of the Playlist |
| name | String | Name of the Playlist |
| cover_art | String | Coverart of the Playlist |
Deployment on the IBM Power AC922
In order to allow a flexible deployment of our solution that is scalable and can be shipped anytime, we decided to use Docker. Especially for local testing and database access, this simplified development substantially.
The current deployment on the IBM server is a production-ready system, where we employ an NGINX instance that acts as a reverse proxy to handle load balancing, caching, and preventing direct access to internal resources. The application itself runs on a Gunicorn WSGI HTTP Server, which is broadly compatible with various web frameworks, simply implemented, light on server resources, and fairly speedy. Gunicorn is based on a pre-fork worker model, which makes the server more stable and scalable [15].
Training and evaluating machine learning models can be a very computationally intensive task, therefore we rely on the computing power of the TUM instance that was provided to us. Currently, the IBM instance hosts our backend to make it available over the internet to our Frontend application, which then just needs to call the API. More importantly, the instance and it’s specialised hardware is used to train our advanced machine learning models, which will be explained in the next chapter.
3.3. External APIs
We have incorporated two external APIs into our application: AudD and Spotify. Both APIs and their functionality used for Spektrum are explained in the following.
AudD
AudD is a music recognition API which can detect 50 million tracks. This API allows us to identify the song that the user recorded. On top of that, AudD also provides Spotify specific information such as the Spotify ID of the recognised song and the corresponding album cover [16]. On the one hand, this allows us to provide the user with a Shazam-like experience when using our app. On the other hand, the obtained song information is a core input for our recommender system (more details in the next chapter). Using the API with Python is very straightforward:

As the screenshot implies, AudD can only be used with an API token. We decided to go for the individual developer subscription plan which costs $2 per month and includes 1,000 requests per month. Every additional 1,000 requests costs $5. For testing and demonstrating our application, this plan provides the best utility-price ratio for us.
Spotify
Spotify is the largest music streaming service that has a music library of 50 million tracks [17]. The Spotify API allows making use of this large music library in various ways. For our application, 4 features of the Spotify API have been particularly valuable [18]:
Detailed Song Information: On top of general information like artist, album and year, the Spotify API also provides a detailed song analysis for each track. For instance, Spotify assigns danceability and loudness scores between 0 and 1 to each song. This information provide the data basis for the playlist generation feature in our app.
30 Second Song Previews: For nearly every song the Spotify API provides a 30-second song preview (for example this is the preview of Bohemian Rhapsody by Queen). These song snippets are useful for our application in two ways. First of all, these previews enabled us to create a large variety of music quizzes. Furthermore, we used those previews to build our own music library of 5,000 songs from different genres which served as a data basis for the training of our advanced genre classifier.
Recommendations: Spotify provides endpoints for recommending artists and songs. While we mainly focused on our own recommender logic, these recommendations help us to offer playlist recommendations as well and also serve as some sort of fallback option in case we cannot generate any recommendation for the recorded song. This is especially relevant for newer songs as the data basis for our own recommender system only contains songs from 2015 or earlier (More Details in chapter 4).
User Library: We are able to fetch the entire music library of the user via the API. This helps us to analyse the musical preferences of the user for numerous statistics, use the user library as a data basis for generating playlists and incorporate songs from the user library into song quizzes.
To link Spotify with our application, we invoke the Spotify OAuth authentication process [19]. We provide a functionality to login to Spotify within our app, which then, in turn, redirects to the login page of Spotify, afterwards the previously defined redirect URI is used and the user gets sent back to our app. The response received from the Spotify server consists of two tokens: an auth token and a refresh token. The former is used to authenticate requests to the Spotify API and the second one is generally used to renew the authentication token in case it expires. The tokens are stored and managed on the backend for each user.
4. Data Science
In this chapter, we will illustrate all of our data science implementations. First, we will present our approach and results for our two main machine learning tasks before further data related implementations are illustrated that extend the functionality of Spektrum. We have set up a separate repository for all data science topics which you can find in our submission. There are Jupyter Notebooks for every topic that is covered in this chapter.
4.1. Machine Learning
There are two large machine learning topics that we dealt with during this project: music genre classifications and music recommendations. Implementation details of both are given in the following.
Music Genre Classification
Music genre classification represents the core subject of this project. For our first prototype which was shown in the intermediate presentation, we created a model based on the provided Jupyter Notebook. After the intermediate presentation, we built a more advanced classifier that is trained with more data and can predict more genres. Both classifiers are described in the following.
Basic Genre Classifier
The initial genre classifier was trained with the GTZAN dataset. This dataset contains 1,000 30-second song snippets from 10 different genres: Blues, Classical, Country, Disco, Hiphop, Jazz, Metal, Pop, Reggae and Rock [20].
After we looked into the provided Jupyter Notebook, we noticed that the already predefined and precomputed test and validation sets only made up 2.5% of the entire dataset. In order to get a better feeling of the performance of a GTZAN based classifier and to gain experience to build a genre classifier from scratch, we decided to download the GTZAN audio files and perform all necessary steps from a labelled dataset to a trained classifier.
The general approach of the classifier is to create a spectrogram of a raw audio file which is then fed into a neural network to predict the probability for each of the ten genres. For training, 5 random 2-second snippets of each song were randomly sampled and then transformed into spectrograms. A spectrogram is a “visual way of representing the [...] loudness of a signal over time at various frequencies” [21]. These spectrograms are mapped onto the Mel-Scale to represent human-hearable frequency differences better [22]. The following mel-spectrograms of 4 different song snippets already indicate differences between genres very clearly:


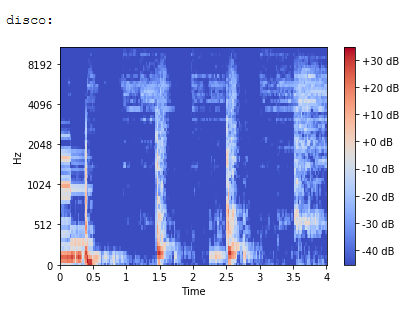
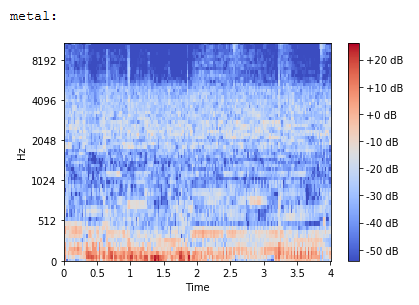
After calculating all mel-spectrograms we split up the dataset into a training and a test set. 80% were used for training and 20% were used for testing. We used a convolutional neural network as our classifier as this architecture performs very well on images [23]. The main purpose of transforming raw audio into spectrogram images is to make use of this strength. Our trained classifier achieved a test accuracy of 75%. The confusion matrix for all predictions on the test set is illustrated below:
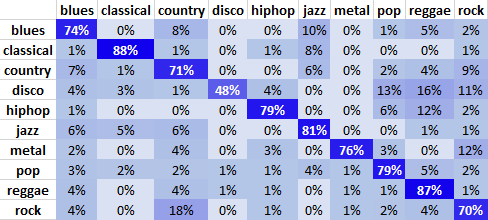
Apart from disco, all other genres achieved an accuracy level equal to or higher than 70%. Furthermore, it seemed logical that the classifier sometimes struggled to distinguish country and rock, blues and jazz or disco and pop.
We persisted the trained model as an h5 file so that we could simply load it into our backend to perform predictions. As explained in the previous chapter, we created an API endpoint for genre classification which expects the recorded audio file from our mobile application in the request. After the API call, spectrograms from 3 different 2-second time frames of the recording are calculated and then used as an input for the trained model. These atomic predictions are then averaged to derive the final genre predictions which are finally returned by the API.
After trying out the classifier a couple of times, we noticed that the volume of the recording heavily influenced our genre classification. For instance, if the recording was too silent it was usually classified as a classic song independent of the actual genre. That’s why we introduced audio normalization with ffmpeg before we calculate the spectrograms. This additional processing step helped to mitigate the issue significantly.
Advanced Genre Classifier
After our intermediate presentation, we wanted to build a more sophisticated genre classifier. While we decided to stick to our general training process, neural network architecture and API logic, we identified two main improvements fields. On the one hand, we wanted to extend our dataset because the GTZAN dataset with its 1,000 songs is rather small and neural networks benefit strongly from more data, e.g. due to reduced risk to overfit. On the other hand, we also wanted to be able to classify more than 10 genres. For both purposes, the Spotify API has been proven very beneficial.
The Spotify API allows retrieving song previews for nearly all its songs via URLs. For example, this is the preview of Bohemian Rhapsody by Queen. We imported the Python package urllib to be able to download such a preview as an MP3 file.
We decided to use genre-specific Spotify playlists and download their respective song previews to build up our own genre dataset. Initially, we tried to fully automate this process by searching via the Spotify API for playlists that simply contain a specific genre (e.g. “pop”) in their title. However, we realized that the automatically fetched playlists (especially the ones created not by Spotify but by users) often contain songs from multiple genres which led to significantly lower performance results. That’s why we decided to manually search for playlists to make sure that only songs from a specific genre are contained in there. After many iterations of trying out different genre and playlists sets and evaluating the resulting classifier performance, we finally decided to go for a set of 100 manually selected playlists from 20 different genres. We extended the existing GTZAN genre set with ten additional genres which on the one hand provide valuable additions to our application and on the other hand are reasonably easy to differentiate by our model: Ambient, Bluegrass, Bavarian, Dubstep, Guitar, Opera, Salsa, Samba, Tango and Techno.
Downloading the songs from the manually selected playlists resulted in a database which consists of 5,000 songs, 250 from each genre. After that, we reused the melspectrogram creation and training workflow that we already created for the GTZAN based classifier and also reused the neural network architecture. We only added an additional audio normalisation step for the downloaded Spotify samples to make sure that the model was already trained with normalised audio files that it has to handle later with the normalised recordings of the user anyway.
In order to train our model on the provided IBM Server we have created a dedicated genre classifier API endpoint:

One can choose to run the full process (including the download of Spotify samples, the calculation of the spectrograms and finally the training), an abbreviated process (calculating the spectrograms on the already downloaded Spotify samples and then train the model) and the core process (just training the model on the already calculated spectrograms). We have configured a goal test accuracy of 70% via a callback so that the training stops once it achieves this performance. In the end, the classification report, as well as the confusion matrix are saved and the model is persisted under the folder genreClassifier/API. This API setup allows to make changes at different points of the training process (e.g., extending the Spotify playlist set, changing the calculation parameters for the spectrograms or adjusting the architecture of the neural network) and directly trigger a new training process while making use of the powerful IBM resources.
Training our neural network resulted in a test accuracy of 71% which is just slightly lower than the classifier based on the GTZAN dataset that can only distinguish half of the genres. The confusion matrix for all test set predictions is illustrated below:
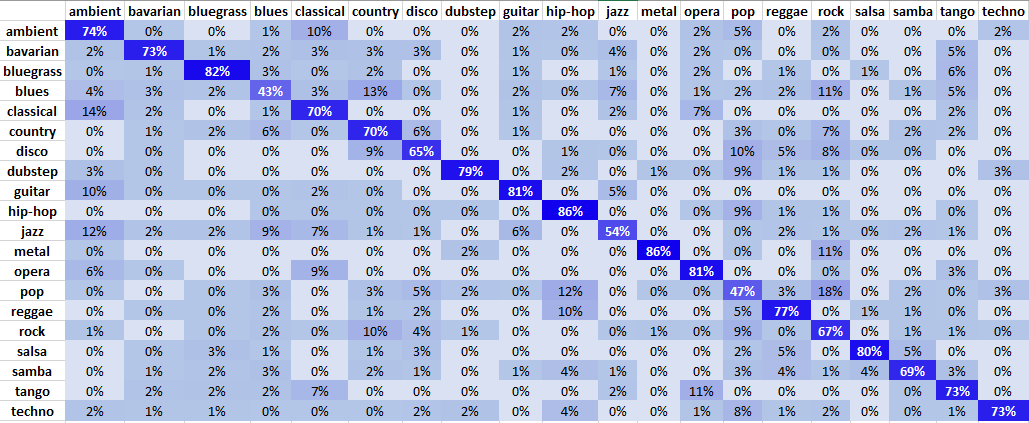
All of the 20 different genres are classified correctly with a probability higher than 43%, 15 genres even with a probability of over 70%. On the one hand, the classifier is particularly good at correctly classifying metal, hip-hop, guitar, bluegrass and opera songs. On the other hand, blues and pop music are the two genres that are misclassified the most. Blues is often confused with country, rock and jazz which is not too surprising due to the inherent similarities of these genres. Pop music is frequently confused with rock and hip-hop music. Since Pop music can be seen as a meta genre in general, these misclassifications also appear logical.
In order to test our genre classifier within the app, here is a list of songs from each genre that our classifier is able to distinguish:
- Ambient
- Bavarian
- Bluegrass
- Blues
- Classical
- Country
- Disco
- Dubstep
- Guitar
- Hip-Hop
- Jazz
- Metal
- Opera
- Pop
- Reggae
- Rock
- Salsa
- Samba
- Tango
- Techno
Music Recommendation System
To generate recommendations based on the recorded song of the user we make use of a combination of collaborative filtering, content-based filtering, and Spotify based recommendations. After describing each of those on a conceptual level, we will present what we do exactly to derive recommended artists, recommended songs and recommended playlists.
The core prerequisite for our song-based recommender system is that the recorded song is identified by the AudD API. For both collaborative filtering and content-based filtering the identified song is looked up in the respective dataset to derive recommendations. In case the AudD API failed to identify the song based on the recording we generate default recommendations which will also be discussed at the end of this chapter.
Collaborative Filtering
In order to implement collaborative filtering, we needed to find a database of users and their musical preferences. After researching and evaluating a few datasets, we considered the ThisIsMyJam dataset as the most promising one for that purpose.
ThisIsMyJam has been a social music network that existed between 2011 and 2015 where users could share their favourite songs (so-called “jams”) with other users [24]. It has been used by over 130,000 people which shared nearly 800,000 different songs via the platform. After the website was taken down, an entire dump of their database was published for research purposes. This dump consists of three .tsv files from which the jams.tsv file provides the greatest value for our recommender system. A small excerpt of the most relevant columns is shown below:

This triplet-structure represents a perfect basis for collaborative filtering. The dataset consists of over 2,000,000 user-song combinations.
The song recommendation logic for a recognised song consists of 2 steps:
- Find all users that have declared the recognised song as one of their jams
- Find the most popular songs among this set of users except the recognised song
For example, when we use “Don’t Stop Me Now” by Queen as the input song, the following songs are generated as the best recommendations by this collaborative filtering logic:
- David Bowie - Heroes
- Pulp - Common People
- Queen - Bohemian Rhapsody
- Queen - I Want to Break Free
- Electric Light Orchestra - Mr. Blue Sky
This recommendation logic for songs can also be applied on an artist level. The two processing steps are then adopted as follows:
- Find all users that have at least one jam from the artist of the recognised song
- Find the most popular artists among these people except the artist of the recognised song
For the Queen example, these are the best artist recommendations according to collaborative filtering:
- David Bowie
- The Beatles
- Led Zeppelin
- The Rolling Stones
- Pink Floyd
Due to the very fitting song and artist recommendations that we also observed for numerous other examples we decided to incorporate this collaborative filtering logic into our overall recommender system.
Content-Based Filtering
In order to perform content-based filtering, a song database with their acoustic features was required. One of the largest collections of acoustic information is AcousticBrainz which is a crowdsourcing project where everyone can contribute to the database [25]. In 2015, AcousticBrainz has published two dumps of their database, one with high-level acoustic information (over 10 GB) and one with low-level acoustic information (over 100 GB). Because the import process of the high-level JSON into a Pandas data frame already took four entire days we decided to stick with that version for our recommender system. A short excerpt of the imported data is shown in the following:
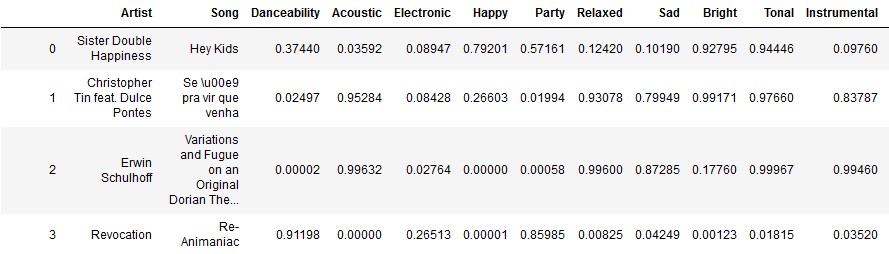
Ten meta attributes are provided for each song which resemble the acoustic features that Spotify stores for its songs as well. The AcousticBrainz dataset consists of nearly one million songs.
In order to derive song recommendations based on a particular song, we defined a distance metric between songs. The distance between two songs is defined as the sum of absolute deviations regarding the ten song meta attributes. The songs which have the smallest overall distance to the recognised song are the most similar and thereby, the most suitable recommendations.
For our example song “Don’t Stop Me Now” by Queen these are the best fitting recommendations according to our distance metric:
- Old Man Wizzard - The Bearded Fool
- Colour Haze - God’s Eyes
- Cold - The Day Seattle Dies
- AC-DC - Live Wire
- Godsmack - What If?
It is easily apparent by this example that this content-based filtering approach can lead to song recommendations which are rather unpopular respectively niche. However, we think that these songs indeed have certain similarities with “Don’t Stop Me Now” by Queen. In general, we consider content-based recommendations as a valuable addition to our overall recommender system as they engage the user to discover entirely new songs that they might have never heard of but hopefully likes as well. These kinds of recommendations would probably never be generated by a collaborative filtering recommender as the songs are too unpopular.
Spotify-API Recommendations
When reading the documentation of the Spotify API we found several interesting recommendation endpoints which we also wanted to include in our application. In general, Spotify based recommendations represent a fallback for our own generated recommendations. As described, both the ThisIsMyJam and the AcousticBrainz dataset are from 2015. Therefore, it is unfortunately not possible to generate recommendations for songs from 2016 or newer with our collaborative or content-based filtering logic. Recommendations from the Spotify API help us to bridge this gap so that the user will always receive recommendations whenever they record a song.
Three Spotify recommendation endpoints are particularly interesting for our overall recommender system:
Related Artists: The Spotify API allows to find related artists for a particular artist.
Song Recommendations: The Spotify API allows to find recommended songs based on a particular song.
Playlists: The Spotify API allows to search for playlists based on a particular search string. If we use the output of our genre classifier as a search string, we are able to find playlists that contain songs from the same genre as the recorded song.
Combined Recommender System
The following overview illustrates which recommendation logics have been incorporated into which recommendation types:
| Recommendation Type | Recommendation Logic |
| Artists Recommendations | Default: Collaborative Filtering based on ThisIsMyJam → 10 Recommendations Fallback (in case of no generated recommendations): Related Artists based on the Spotify API |
| Song Recommendations | Default: Collaborative Filtering based on ThisIsMyJam Content-Based Filtering based on AcousticBrainz → 10 recommendations each → Remove duplicates Fallback (in case of no generated recommendations): Song Recommendations based on the Spotify API |
| Playlist Recommendations | 10 Playlists whose title contain the AI-classified genre of the song based on the Spotify API |
In order to generate a consistent output for all our recommendations independent of the internal logic, we always search for a recommended artist or song via the Spotify API to fetch the corresponding Spotify URI (so that the user can click on any recommendation) as well as the cover art. That’s why a Spotify connection of the user is required for our complete recommender system.
Default Recommendations
As already said, all recommendations described above only work if the song could be identified in the first place by the AudD API. In order to present recommendations to the user even if this identification fails we make use of the Spotify API again. For artist and song recommendations we fetch the Global Chart Playlist from Spotify and display the artists and songs from that list. For playlist recommendations, we show featured playlists from Spotify that we can also retrieve via a dedicated API endpoint.
4.2. Further Implementations
On top of our genre classifier and recommender system, we have four further data-related implementations. While the functionality of the whole app will be presented including screenshots in greater detail in the subsequent chapter, the following information is meant to provide explanations about the necessary data operations to realize the functionality.
Quiz Generation
We have integrated a large quiz section into our app.
The first quiz allows the user to compete against our trained neural network in classifying the genre of songs. We use our downloaded Spotify samples as a data basis for this quiz and stored them on AWS so that we do not have to return audio files, but only AWS links in our AI genre quiz API endpoint. In order to enable a fast quiz experience, we precalculated all predictions of our classifier on the Spotify samples and stored them in our backend. The creation of a quiz finally works as follows:
- Choose a random song from all Spotify samples
- Fetch the AWS link of the song
- Lookup the four genres with the highest probability according to our genre classifier
- If the correct genre of the song is not contained in that set, replace the genre with the lowest probability with the correct genre
- Shuffle the four genre options
- The AWS link of the song together with the four genre options constitute a quiz round
- Repeat this procedure to generate a quiz with ten quiz rounds
On top of this AI quiz, we used the Spotify API to generate a multitude of different musical quizzes. The general process of generating these quizzes is similar to the one described above. However, the underlying data basis is not stored on AWS, but fetched in real-time via the Spotify API. Like for our genre classifier, we use Spotify playlists as our data source for this feature. For instance, we created a “Guess the Artist” or “Guess the Song” Quiz for popular songs by fetching the audio previews and meta-information (artist and song) from each song of this playlist. By choosing four random artists/songs out of that set as well as the correct artist/song of the resulting subset one can create arbitrarily many quiz rounds. Because there are genre and decade specific playlists on Spotify we were also able to create “Guess the Genre” and “Guess the Decade” quizzes. Finally, we mixed different data sets with different quiz types. Consequently, we have created quizzes like “Guess the Reggae Song” or “Guess the Artist for Songs from the 1980s”.
As two special quizzes, we have implemented an “8 Bit Quiz” as well as a “Reverse Song Quiz”. While the 8-bit quiz is generated by fetching songs from this artist on Spotify, we reversed some popular songs on our own and stored them on AWS for the “Reverse Song Quiz”.
User Library Import
When the user signs in with Spotify, this triggers an import process of their music library within our backend. Next to general information like artist, song, year, decade, genre and the popularity of the song, the audio-preview of each song is stored as well in our database. This allows us to generate music quizzes based on the song library of the user.
Furthermore, the following audio features of each song are also stored in our database:
- Energy
- Danceability
- Instrumentalness
- Liveness
- Valence
- Acousticness
- Loudness
- Speechiness
- Tempo
More information about these features is provided in the Spotify Documentation.
User Statistics
Based on the imported user library we create statistics regarding the genre and decade preferences of the user. Furthermore, we access the Spotify API to fetch the favourite artists and songs of the user.
Playlist Generation
In order to generate playlists, we apply different filters to the imported User Library. For each of the audio features of a song as well as for the popularity score, a minimum and a maximum value is provided by the application and then applied to the library to find songs that match the given criteria. One can also filter particular decades in a similar fashion.
After setting all filters, the Spotify API allows us to create a playlist with all matching songs directly within the users Spotify account.
5. Spektrum
In this chapter, we will focus on the actual usage of our app by illustrating the workflow and use cases with screenshots. The screenshots of the Identify and Discover part are taken on an Android phone (BQ Aquaris X Pro, 5.2” screen size, Android 8.1.0). The screenshots in the Play part are taken on an iPhone (iPhone 7, 4.7” screen size, iOS 13.3). This underlines that our app is designed and tested for both Android and iOS smartphones.
Upon the very first start of our application, the user will be prompted to grant recording permissions in order for our app to function. After that, an overlay that asks the user to sign in with Spotify in order to access all functionalities of the application will be shown. If the user presses “SIGN IN WITH SPOTIFY”, they are redirected to a standard sign-in/registration form provided by Spotify. Upon successful authentication, the user will end up on the homepage of our app - the Identify tab. In case the user chooses to “Sign in Later”, they will be directly lead to the Identify tab. The main functionalities (genre prediction/song identification) and the quiz against the AI model will be available, all other actions will lead back to the “Sign in with Spotify” overlay.

Right: “Sign in with Spotify”-overlay
5.1. Identify
The middle tab of the bottom tab bar is called “Identify”. This tab’s main feature is song identification and genre prediction. To identify a song that the user is currently listening to (e.g. on the radio), the round button in the centre of the screen should be pressed to start a recording. The recording will automatically be submitted to the Spektrum API for analysis. A pulse animation around the button indicates that the process is ongoing. Pressing on any other tab or the “Song History” button will interrupt the recording and no results will be shown.
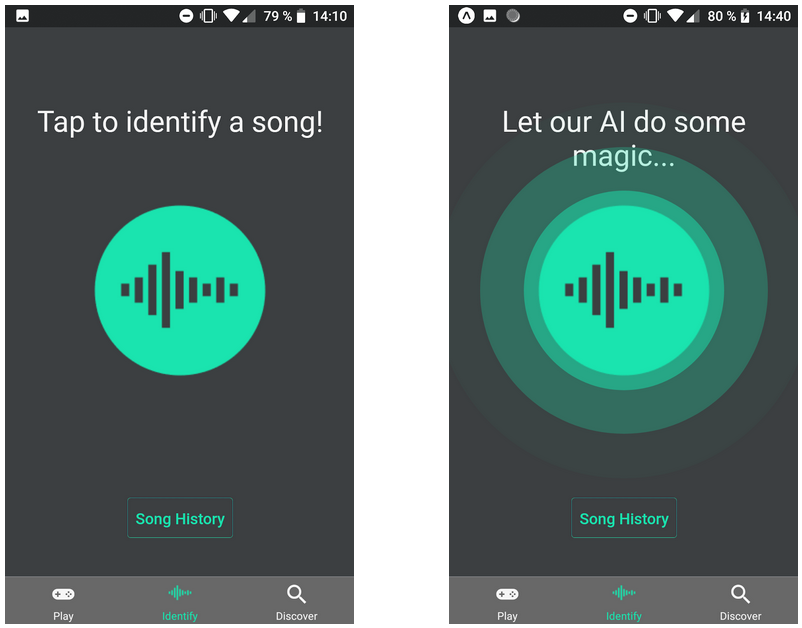
Right: Identify screen when working
Song Details
Upon receiving a response from the Spektrum API, the Song Details screen will automatically be shown. If the song is recognized, the user will be presented the title, artist, cover art and the predictions of our genre classifier. By tapping on the cover art, the song will be opened in Spotify. If the song is not recognized, the genre will still be classified - a placeholder and the predictions are shown

Right: Song Details screen for unrecognized song
Song History
By pressing the back arrow in the top left corner or by selecting the Identify tab in the tab bar, the user will get back to the initial screen. Below the recording button, they have the option to view their previously identified songs by pressing the “Song History”-button. A scrollable list of all the songs is shown. Upon selecting a song from the list, the previously described Song Details screen including the genre prediction will be shown.

5.2. Discover
The rightmost tab in the bottom tab bar is called “Discover”. This tab invites the user to explore additional information and functionalities all around the topic of music. It is divided into three sections: recommendations / worldwide trends, playlist generator and personal preferences. To be able to see the content, a user has to be signed in with Spotify.
Inside the Discover tab, the user will find multiple so-called carousels that consist of cover arts and are scrollable in a horizontal direction. Every cover art is linked to the respective Spotify playlist/song/artist and can be pressed to open this specific item in Spotify.
Recommendations and Worldwide Trends
The first section is dependent on whether a song is currently selected or not. The user is able to select a song by either identifying a new song or by selecting one of the previously identified songs in the Song History in the Identify tab. After selecting a song, recommendations based on the title, artist and genre will be shown in the first Discover section. The currently selected song and artist will be displayed right underneath the heading (in green). In case title and artist should be too long for the screen width, the text will automatically move continuously in a horizontal direction to make sure all the details can be read. In case no song is selected e.g. on a fresh start of the app or by pressing the small “X” next to the green song title/artist, worldwide trends based on continuously updated playlists will be shown.

Right: Worldwide trends (no song selected)
Playlist Generator
The second section of the Discover tab is used to generate custom playlists. If no playlists have been generated yet, a simple “Create Playlist” button is displayed. As soon as the user created their first playlist, a carousel that is updated with each new playlist will be shown.

Right: Playlist Generator section including previously created playlists
Upon pressing the “Create Playlist” button, the user is asked if they want to base their new playlist on a template or if they want to use the default settings and customize it completely in the next step. After selecting a template or the default version, the user is presented with a variety of criteria that their new playlist should match. As an example, if the Pop template would be selected, the application would preselect only newer decades and a high popularity.
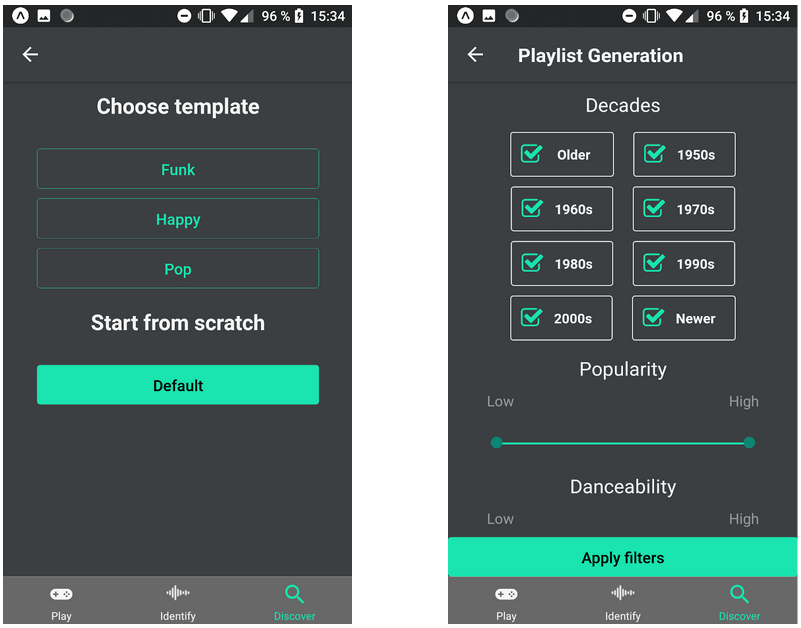
Right: Parameter selection in Playlist Generator
The user can scroll down to customize more parameters and apply the filters by pressing “Apply filters”. As a result, all songs from the user’s personal Spotify library that match the criteria will be shown. If the user is not happy with the song selection (or if no songs match the criteria), they might go back with the back arrow in the top left corner in order to adapt their parameter selection.

Right: Matched Songs screen
Upon pressing the “Create Playlist” button, the user is asked to enter a name for the new playlist. When this is done, the user will be presented with their new playlist and is able to tap on the cover art to open the playlist in Spotify or chose to return to Discover by pressing the “Discover More” button.

Right: Final screen of Playlist Generator
Personal Preferences
The last section of the Discover tab shows personal preferences and statistics based on a user’s Spotify library. As mentioned before, all cover arts in the carousels are clickable.

Right: Bottom part of Personal Preferences section
Additional Remarks
The Playlist Generator and Personal Preferences sections are dependent on the user’s personal Spotify library (=liked songs). Dependent on the number of songs, loading this library can be time-consuming (several minutes). Therefore, the user might see a loading message while this process is ongoing.
Furthermore, if the user does not have any songs in their library, they will be shown a button to “Open Spotify” to add some songs. Depending on the number of songs that were added, it might require a restart of Spektrum before the personal preferences are updated.

Right: Screen if no songs are in user library
5.3. Play
The first page when opening the quiz section is the main game menu where the player can initially choose between the AI genre quiz (user competes against our current AI model), single-player quizzes, and multiplayer quizzes (see screenshots below). The AI genre quiz can be played at any time, however, for all other quizzes a Spotify login is necessary. If the user has not signed in yet, we ask to complete the login by showing the Spotify login overlay as described in the introduction of this chapter.
Genre Quiz
The AI genre quiz consists of ten rounds. Pressing the play button starts a new game and each next round, subsequently, the music starts to play automatically. By pressing one of the four buttons, the music stops and the quiz round is evaluated. The true answer is highlighted with a white border, the user’s choice is marked with the arrow on the left, the model’s prediction is marked with the arrow on the right and scores are updated accordingly. After the last round, an overlay displays the quiz results and gives two options: play again or return to the main menu.

Right: First round after pressing play

Right: Quiz results
Submenu and Singleplayer
If the user is signed in with Spotify and decides to play a single- or multiplayer game, they are redirected to a submenu where the specific quiz type can be selected (all these types are available for multiplayer and singleplayer). While song and artist quizzes are each divided into four categories with regard to the quiz song basis, two of these categories are available for genre and decade quizzes, and the 8-bit quiz, as well as the reverse song quiz are unique quizzes. Pressing on one of the first four quiz types opens the respective quiz options (green font color) and closes any other open options.

Right: Submenu with options for genre and decade quizzes
If the user chooses to play a song or artist quiz, that is generated with regard to a specific music genre or decade there is an overlay displayed to select the particular genre (all 20 genres from our advanced genre classifier) or decade (from 1950 to 2010) as shown in the left screenshot below. For single player quizzes, there is no maximum number of rounds since the goal is to set a new highscore. Just like the AI genre quiz, a new round or game is started with the play button. The quiz continues until the user enters an incorrect answer, then the game is reset after a short delay so that the user can still see the correct answer. Highscores are stored separately for each distinct quiz type, i.e. there are also different highscores for e.g. the classical song quiz and the hip-hop song quiz.

Right: "Guess the Artist" single player quiz based on Hip-Hop genre (during round 3)
Multiplayer
The third general type of quiz is multiplayer quizzes, which, as mentioned above, are available as the same quiz types shown in the submenu screenshots above. Again, pressing the play button starts a new round and the quiz ends after ten rounds. The first player needs to press the buttons on the left and the second player plays with the buttons on the right. If the first guess of one of the players is the true answer, the round and the music stops directly (left screenshot). However, if the first responding user gets it wrong, the other player can still take a guess and receive the point of this round when answering correctly (right screenshot).

Right: Multiplayer "Guess the Song" quiz - first answer is wrong, second answer is correct
After a wrong guess, the particular player is blocked from trying again. If both players get it wrong, the true answer is highlighted, the music stops and nobody gets a point. After the tenth and last round, an overlay displays the quiz results and gives the known two options: play again or return to the main menu.

Right: Multiplayer quiz results
6. Results and Discussion
6.1. Results
One core result of this project is our advanced genre classifier that is able to distinguish 20 different genres (Ambient, Bavarian, Bluegrass, Blues, Classical, Country, Disco, Dubstep, Guitar, Hip-Hop, Jazz, Metal, Opera, Pop, Reggae, Rock, Salsa, Samba, Tango, Techno) and has achieved a test accuracy of 71%. As already shown in the Data Science chapter, this is the confusion matrix based on the test set:
The recommender system we have built up is hard to evaluate quantitatively, but can only be evaluated qualitatively. We tested the recommender system for hundreds of songs and consider the generated recommendations fitting in the great majority of cases. The combination of collaborative filtering and content-based filtering results in a mix of popular and niche recommendations that allow the user to extend their musical spectrum.
The quiz section offers a large variety of quizzes for the user. It supports the overall goal of our app as the user can try to improve their musical knowledge in special musical areas such as particular decades or particular genres.
The playlist generator enables the user to explore what characteristics made up songs in a playful way. By setting different filters, the user can, for instance, create decade or mood-specific playlists based on their own song library.
With the user statistics, we allow the user to gain insights about their own musical preferences. Thereby, the user is encouraged to explore musical genres they have not listened to so much yet.
Integrating AudD and Spotify as external APIs into our App as well as employing publically available datasets like AcousticBrainz or ThisIsMyJam have been crucial for almost any of these features. This demonstrates the power of combining existing APIs and datasets to derive entirely new services.
6.2. Personal Evaluation
After working on this project for the last couple of months, we are very happy with our application regarding the experience on the frontend as well as the processing logic in the backend. We invested a lot of time in both of these areas as we consider them equally important for a successful application
For the Frontend, we focused on giving Spektrum a simple, consistent and responsive UI. That’s why we spent a lot of effort into designing each part of the application. For example, the pulsing animation in the Identify Screen has been the result of several iterations of design and evaluation. We also created a new logo after our intermediate presentation to better fit the dark background as well as the overall colour scheme of Spektrum. We used feedback from our friends and families to continuously finetune our UI. In order to optimize the responsiveness of our app, we carefully designed when to perform which API calls. For instance, Redux allowed us to already load the default recommendations (charts and featured playlists) when the user starts the app so that they are already available when they navigate to the Discover tab. Furthermore, we reduced the sizes of the cover arts provided by Spotify to enable a faster rendering.
The functionality provided by our Backend has already been described extensively throughout this documentation. We are not only happy with the sheer amount of features we managed to implement during this project but also with the connections between these features. For instance, the decision to import the music library of the user and store it in our database allowed us to calculate statistics on the preferences of the user, implement our playlist generator and enrich our quiz section with quizzes based on the user’s own songs. We are very glad that we discovered the opportunities of the Spotify API at an early stage of this project as it enabled us to implement a lot of cool things. In particular, the ability to fetch song samples has been essential for optimizing our genre classifier. We are very proud that we have achieved an accuracy level above 70% while simultaneously doubling the set of genres the classifier is able to differentiate.
Finally, the IBM infrastructure helped us to host our backend, train our classifier and make our API globally accessible. We really enjoyed developing an application in the area of musical analysis and are grateful for the possibility and technical environment provided by IBM and TUM.
6.3. Main Challenges
API Hosting/Deployment
Hosting an application in production is always a difficult task. In our case, the production environment was predetermined by the requirement to use the IBM AC922 server provided by the university. The main challenges in this regard were the general process of deployment, the need for specialised audio libraries to process the recordings and furthermore finding packages that were specifically built for the IBM architecture inside the AC922. The general deployment is done via our git repository and the server is then run in production mode, yet this requires a lot of manual action and should be automated in the future, as pointed out in the next chapter. Furthermore, we encountered several problems regarding our reverse proxy setup and HTTPS, which we were kindly helped with by the chair and then managed to resolve by reverting back to HTTP and setting up the correct ports. Another problem we faced were countless python package version mismatches. Especially the python packages Tensorflow and Librosa proved to be problematic, given that they also relied on specific underlying Linux packages. However, after deactivating the default anaconda environment and some more research, we were able to identify the correct package versions needed and were able to successfully install them.
iOS/Android Support
Although the use of Expo is definitely a big-time advantage when it comes to quick setup and rapid prototyping, there are still some challenges to deal with when developing for iOS and Android simultaneously. Due to different underlying implementations of Expo functionalities and React Native packages for each operating system, we encountered several obstacles in the frontend. Although some of our team members were limited in testing possibilities (because iOS functionality cannot be tested without a corresponding Apple device), the solving of problems such as design differences and audio recording settings went relatively efficiently. However, some problems were caused by certain Expo implementation characteristics. For instance, the use of Expo Audio to play sounds for our quiz features work seamlessly on iOS but causes the Android audio player to crash in some rare test cases such as starting several rounds, i.e. playing several new sounds in a matter of seconds. To overcome this limitation it would be necessary to eject the project from Expo and then switch to other React packages that are not compatible with Expo or rely on the Expo developer team to solve the issues which were also reported by several other developers. We think that it was beneficial to leverage Expo to create this sophisticated prototype but we would switch to a more independent setting when moving forward with this project.
Audio Processing
Especially in the beginning, we had difficulties finding audio encodings and formats that were supported via Expo and could be handled by our backend. Recording differences between Android and iOS devices made this issue even more complex. After trying out various settings, we found a way to make it work on both device types. While we record AAC-encoded MP3 files on Android devices, the recordings of iOS devices needed to be saved as MP4 files with an iOS-specific encoding. After we built our advanced genre classifier based on Spotify samples we also needed to adjust the sample rate as well as the bitrate of the recordings so that they match those from the Spotify Samples. This ensures that the classifier only has to deal with audio files that are structurally similar to the ones it was trained on.
In order to handle different volume levels of the recording, we decided to use ffmpeg to normalize the recording before it is converted into a spectrogram. After we managed to run our backend on the IBM Server, the audio processing commands caused several errors. Fortunately, we managed to install ffmpeg as well as some encodings on the IBM machine so that everything works as expected now.
Independent of the aspects described above, a proper audio quality is still needed for best results when using our app. The AudD API sometimes struggles to identify the song if there is a certain amount of background noise. Background noise also influences the results of our genre classifier which is why a silent environment is recommended to use our app.
6.4. Outlook
Genre Classifier Improvements
Currently, our genre classifier can distinguish 20 different genres and is trained on a dataset of 5,000 Spotify Song Samples. As already pointed out, we initially tried during the project to extend both the genre and song set by automatically searching for genre playlists on Spotify but realized significant performance decreases due to “unclean” playlists. However, we achieved very promising results with manually selected playlists from Spotify. Pursuing this approach further could lead to an even bigger genre and song set which helps the classifier to become “cleverer” and more robust. Selecting new genres with care is crucial here because they need to be differentiable from the already existing genres. For instance, we noticed during our tests that the classifier has difficulties to distinguish different rock subgenres. One might also consider performing more fine-tuning regarding the calculation parameters for the spectrograms as well as the neural network architecture in order to improve performance even further. Our dedicated genre classifier API endpoints allow to modify particular parts of the code and then rerun the whole or only parts of the training process again. After training a classification report as well as a confusion matrix for the latest changes are exported. The trained machine learning model is persisted as well and can immediately be used in production for classifying records of the user. In short, this framework simplifies further enhancements of the genre classifier as well as their evaluation and deployment.
Continuous Integration and Deployment Pipeline
To further improve the development process and the quality of our application, we should aim to automate the deployment in order to reduce the time needed to deploy a production-ready application. This can be achieved by setting up an automated pipeline with development, staging and production branches, as well as automated test and builds and an automated machine learning pipeline as described in the chapter above. New commits will then automatically trigger the pipeline and as soon as all tests are passed it can be deployed in a staging area and when the changes are approved, they can be directly published.
Storing the Audio Recordings of the Users
Currently, we are only storing the latest recording of each user in the “recordings” folder of our backend. If the App is used by many people there will be a lot of requests to our song identification and genre classification endpoint. If all recordings alongside the song identification and genre classification information are stored in our database we would be able to analyse the strengths and weaknesses of both systems in a more structured way. For instance, we could measure how background noises influence the probability that a song can be recognised by the AudD API. Collecting a lot of audio recordings alongside the song identification information provided by AudD might also allow us to build our own song identifier that compares a recording of the user with all recordings that we have already collected. If a sufficiently high similarity to an already existing identified recording is given, we can perform song identification without using AudD again. This would make our application more independent.
Online Multiplayer for the Quiz
Currently, our application allows the user to play every quiz in single- or multiplayer mode. This multiplayer mode works offline and requires two people in front of the smartphone. A possible extension for the future would be to build an online multiplayer mode where people from all over the world can compete in musical quizzes. We are convinced that many people would like to compete against their friends and family to test and compare their musical knowledge (for different genres and/or different decades). One can also think of further gamification elements like leaderboards and badges to increase the motivation to use our app.
App Publication
Currently, running Spektrum requires Expo. However, Expo allows building standalone apps for Android and iOS [26]. We already tested this for Android and were able to create an APK. While the majority of features worked, we noticed that some modifications are still necessary to have a fully running standalone application. In particular, the “Sign in With Spotify” functionality is currently coupled with Expo.
We would really like to publish our app in the Android and iOS app stores. The feedback from our friends and families has been very positive and we are convinced that a lot of people would enjoy using our features. Since building our own song identifier will only be possible in the long term after collecting a large set of recordings we would need to earn money with our app to cover the costs of using the AudD API (which can go up to $750 per month depending on the number of requests). Advertisements or a “pro version” with access to our specific quiz types are already two possible options. Due to the large variety of features, we are convinced to find ways to earn money with our app.
As a preliminary form of sharing our app, we used Expo. Under this link you can find a QR code that you can scan with the Expo app (available for iOS and Android) to use Spektrum. More details on that are provided in the appendix.
Responsibilties
| Task | Aaron | Lukas | Moritz | Marte | Thomas |
| Project - Project Leader | X | ||||
| Frontend - State Management | X | ||||
| Frontend - Identify Screen | X | ||||
| Frontend - Discover Screen | X | X | |||
| Frontend - Playlist Generation | X | ||||
| Frontend - AI Genre Quiz | X | ||||
| Frontend - Singleplayer Quizzes | X | ||||
| Frontend - Multiplayer Quizzes | X | ||||
| Infrastructure - IBM Server Setup | X | ||||
| Backend - Authentication (JWT/Spotify) | X | ||||
| Backend - Rest API | X | X | |||
| Machine Learning - Genre Classifier | X | ||||
| Machine Learning - Recommender System | X | ||||
| Documentation - Abstract | X | ||||
| Documentation - Team Introduction and Organisation | X | ||||
| Documentation - 1. Project Topic and Motivation | X | ||||
| Documentation - 2. Features and Functionality | X | ||||
| Documentation - 3. Solution Architecture | X | ||||
| Documentation - 4. Data Science | X | ||||
| Documentation - 5. Spektrum (Identify) | X | ||||
| Documentation - 5. Spektrum (Play) | X | ||||
| Documentation - 5. Spektrum (Discover) | X | ||||
| Documentation - 6. Results & Discussion | X | X |
Bibliography
[1] Huang, D., Serafini, A., & Pugh, E. (2018). Music Genre Classification.
[2] Dong, M. (2018). Convolutional Neural Network Achieves Human-level Accuracy in Music Genre Classification.
[3] McKay, K. & Fujinaga, I. (2006). Musical Genre Classification: Is It Worth Pursuing and How Can It be Improved?.
[4] TyroLabs. (2019). Introduction to Recommender Systems in 2019. https://tryolabs.com/blog/introduction-to-recommender-systems/. Accessed 24 January 2020.
[5] Techopedia. (2019). Collaborative Filtering (CF). https://www.techopedia.com/definition/1439/collaborative-filtering-cf. Accessed 24 January 2020.
[6] Logan, B. (2004). Music Recommendation from Song Sets.
[7] Zichermann, G. & Cunningham, C. (2011). Gamification by Design: Implementing Game Mechanics in Web and Mobile Apps.
[8] Statista. (2019). Most popular Apple App Store categories in November 2019, by share of available apps. https://www.statista.com/statistics/270291/popular-categories-in-the-app-store/. Accessed 24 January 2020.
[9] Koepp, M., Gunn, R., Lawrence, A. Cunningham, V., Dagher, A., Jones, T., Brooks, D., Bench, C., & Graspy, P. (1998). Evidence for striatal dopamine release during a video game.
[10] Khomych, A. (2019). Is Gamification the Only Way for Apps to Survive?. https://blog.getsocial.im/is-gamification-the-only-way-for-apps-to-survive/. Accessed 24 January 2020.
[11] React. (2020). A JavaScript library for building user interfaces. https://reactjs.org/. Accessed 24 January 2020.
[12] Expo. (2020). The fastest way from an idea to a native experience. https://expo.io/features. Accessed 24 January 2020.
[13] Flask. (2020). Flask. https://www.palletsprojects.com/p/flask/. Accessed 24 January 2020.
[14] Swagger. (2020). API Design. https://swagger.io/solutions/api-design/. Accessed 24 January 2020.
[15] Gunicorn. (2020). gunicorn. https://gunicorn.org/. Accessed 24 January 2020.
[16] AudD. (2020). AudD is music recognition API. https://docs.audd.io/. Accessed 24 January 2020.
[17] Spotify. (2020). Company Info. https://newsroom.spotify.com/company-info/. Accessed 24 January 2020.
[18] Spotify. (2020). Web API Reference. https://developer.spotify.com/documentation/web-api/reference/. Accessed 24 January 2020.
[19] Spotify. (2020). Authorization Guide. https://developer.spotify.com/documentation/general/guides/authorization-guide/. Accessed 24 January 2020.
[20] Marsyas. (2015). Data Sets. http://marsyas.info/downloads/datasets.html. Accessed 24 January 2020.
[21] PNSN. (2020). What is a Spectrogram?. https://pnsn.org/spectrograms/what-is-a-spectrogram. Accessed 24 January 2020.
[22] Gartzman, D. (2019). Getting to Know the Mel Spectrogram. https://towardsdatascience.com/getting-to-know-the-mel-spectrogram-31bca3e2d9d0. Accessed 24 January 2020.
[23] Asiri, S. (2019). Building a Convolutional Neural Network for Image Classification with Tensorflow. https://towardsdatascience.com/building-a-convolutional-neural-network-for-image-classification-with-tensorflow-f1f2f56bd83b. Accessed 24 January 2020.
[24] ThisIsMyJam. (2015). The Jam Archives. https://www.thisismyjam.com/. Accessed 24 January 2020.
[25] AcousticBrainz. (2020). Welcome to AcousticBrainz!. https://acousticbrainz.org/. Accessed 24 January 2020.
[26] Expo. (2020). Building Standalone Apps. https://docs.expo.io/versions/latest/distribution/building-standalone-apps/. Accessed 24 January 2020.
Appendix and Credentials
GitLab Repositories
| Repository | Link |
| Frontend | https://gitlab.lrz.de/ibm-gang/genre-detector-frontend |
| Backend | https://gitlab.lrz.de/ibm-gang/genre-detector-backend |
| Data Science | https://gitlab.lrz.de/ibm-gang/data-science |
Frontend ReadMe

Backend ReadMe
